In the realm of data security and privacy, deterministic masking stands out as a pivotal technique. As businesses and organizations increasingly move towards digital transformation, safeguarding sensitive data while maintaining its usability has become crucial. This article delves into the essence of deterministic data masking, its importance, how it’s implemented, and how it compares to alternative masking techniques.
What is Deterministic Data Masking?
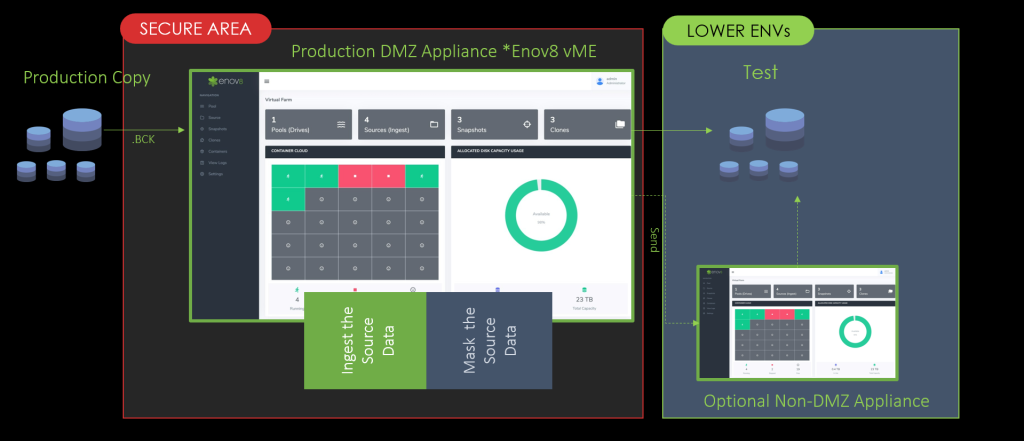
Deterministic data masking is a method used to protect sensitive data by replacing it with realistic but non-sensitive equivalents. The key characteristic of deterministic masking is consistency: the same original data value is always replaced with the same masked value, regardless of its occurrence across rows, tables, databases, or even different database instances. For example, if the name “Lynne” appears in different tables within a database, it will consistently be masked as “Denise” everywhere.
This technique is particularly important in environments where data integrity and consistency are paramount, such as in testing and quality assurance (QA) processes. By maintaining consistent data throughout various datasets, deterministic masking ensures that QA and testing teams can rely on stable and consistent data for their procedures.
Why is Deterministic Masking Important?
- Security and Irreversibility: The primary objective of data masking, deterministic or otherwise, is to secure sensitive information. Masked data should be irreversible, meaning it cannot be reconverted back to its original, sensitive state. This aspect is crucial in preventing data breaches and unauthorized access.
- Realism: To facilitate effective development and testing, masked data must closely resemble real data. Unrealistic data can hinder development and testing efforts, rendering the process ineffective. Deterministic masking ensures that the fake data maintains the appearance and usability of real data.
- Consistency: As seen with tools like Enov8 Test Data Manager, deterministic masking offers consistency in masked outputs, ensuring that the same sensitive data value is consistently replaced with the same masked value. This consistency is key for maintaining data integrity and facilitating efficient testing and development processes.
Implementing Deterministic Masking
The implementation of deterministic masking involves several levels:
- Intra-run Consistency: For a single run of data masking, specific hash sources ensure that values based on these sources remain consistent throughout the run.
- Inter-run Consistency: By using a combination of a run secret (akin to a seed for randomness generators) and hash sources, deterministic masking can achieve consistency even across different databases and files. This level of determinism assures both randomness and safety, as hash values are used merely as a seed for generating random, non-reversible masked data.
Alternative Masking Techniques
While deterministic data masking offers numerous advantages, particularly in consistency and security, it’s important to understand how it compares to other masking techniques:
Dynamic Data Masking (DDM)
DDM masks data on the fly, maintaining the original data in the database but altering its appearance to unauthorized users.
Random Data Masking
This method randomly replaces sensitive data, useful when data relationships aren’t crucial for testing.
Nulling or Deletion
A straightforward method where sensitive data is nulled or deleted, often used when interaction with the data field isn’t required.
Encryption-Based Masking
Involves encrypting data, accessible only to users with the decryption key, offering high security but complexity in management.
Tokenization
Replaces sensitive data with non-sensitive tokens, effective especially for payment data like credit card numbers.
Conclusion
Deterministic data masking has emerged as a vital tool in the data security landscape. Its ability to provide consistent, realistic, and secure masked data ensures that organizations can continue to operate efficiently without compromising on data privacy and security. As digital transformation continues to evolve, the role of deterministic data masking in safeguarding sensitive information will undoubtedly become even more significant. Understanding and selecting the right data masking technique, whether deterministic or an alternative method, is a key decision for organizations prioritizing data security and usability.